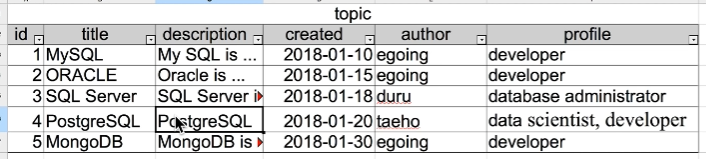
데이터가 중복돼서 등장하는 부분이 있다.
(author & profile의 id 1, 2, 5 부분)
→ 개선할 것이 있다.
중복의 악취가 나면 그것은 무언가 개선할 것이 있다는 강력한 증거가 된다.
데이터 중복의 문제
- 굉장히 복잡하고 용량이 큰 데이터가 천만 번 등장한다면 얼마나 기술적&경제적인 손해일까.
- 데이터의 수정이 필요할 때 천만 번 해야할 것이다. (수정의 어려움)
- 데이터의 용량이 크다면 두 개가 같은 데이터라는 것을 확신하기 어려울 수 있다.
- 동명이인이 여러 명 있을 수 있다.
< 해결 방법 >
먼저, author들에 대한 정보를 별도의 표로 뺀다.

이제 topic에 대한 정보를 갖고 있는 테이블을 만든다.
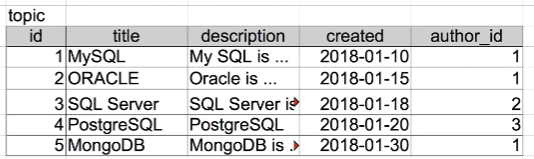
표가 조금 복잡해지긴 했지만
중복된 데이터들이 사라지고
그것이 author 테이블의 식별자인 id 값으로 대체되었다.
유지보수하기가 훨씬 쉬워졌다.
이름과 프로필이 같은 사람을 구별할 수 있어졌다.
하지만 단점도 생겼다. (trade off)
기존 테이블의 장점
- author와 profile도 하나의 표에 다 드러나기 때문에
직관적으로 데이터를 볼 수 있다.
∴ 데이터를 별도의 테이블로 보관함으로써 중복을 발생시키지 않으면서도
실제로 데이터를 볼 때는 하나의 데이터, 하나의 표로 합쳐진 결과를 보고 싶다.
저장은 분산해서, 보여줄 땐 합쳐서
→ MySQL과 함께라면 가능하다.

SELECT * FROM topic LEFT JOIN author ON topic.author_id = author.id;

'MySQL > 생활코딩' 카테고리의 다른 글
| 생활코딩 - MySQL - 17. 관계형 DB의 꽃, JOIN (0) | 2020.06.08 |
|---|---|
| 생활코딩 - MySQL - 16. 테이블 분리하기 (0) | 2020.06.08 |
| 생활코딩 - MySQL - 14. 수업의 정상 (0) | 2020.06.08 |
| 생활코딩 - MySQL - 13. DELETE (0) | 2020.06.08 |
| 생활코딩 - MySQL - 12. UPDATE (0) | 2020.06.08 |




댓글