* 오늘의 진도
PHP
정규표현식 - 검색, 치환
19. 정규표현식 - 검색
정규표현식에서 단어의 경계를 의미하는 word boundary 패턴을 이용해서 텍스트를 검사하는 예제를 살펴보자.

1) web이라는 단어를 검색하고 싶은데,
이 단어가 (2)의 website처럼) 다른 단어와 결합되어 있지 않은
web이라는 단어만 검색하고 싶다면
\b는 단어의 경계를 나타내는 것이기 때문에
\bweb\b를 사용하면 된다.
→ 결과: 1
2) 결과: 0
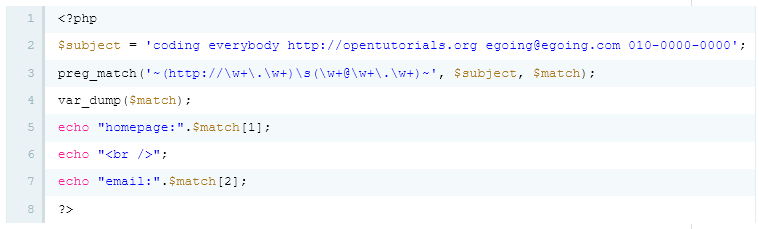
preg_match의 세번째 인자로 $match가 들어갔다.
이 변수의 이름은 꼭 match일 필요는 없고, 위에서 따로 선언할 필요도 없다.
여기에 적어주기만 하면 preg_match 함수가 내부적으로 그런 변수를 생성해서
그 변수에 우리가 검색한 결과를 채워넣어서 리턴하게 된다.


이 텍스트에서 도메인을 추출하고 싶다면?

방법1) escaping

방법2) 구분자를 / 대신 ~로 쓴다.

opentutorials까지 선택하려면 \w(알파벳, 숫자, _)를 사용하고, 1~多를 의미하는 +를 붙인다.
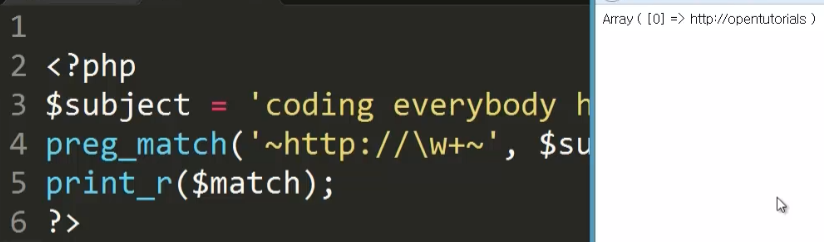
.은 \w에 포함되지 않기 때문에 여기까지만 검색되었다.

그냥 .을 써도 에러가 나지는 않지만,
정규표현식에서 .은 문자/공백/특수문자 등 모든 캐릭터를 의미하므로
.을 강제하려면 \.으로 해준다.


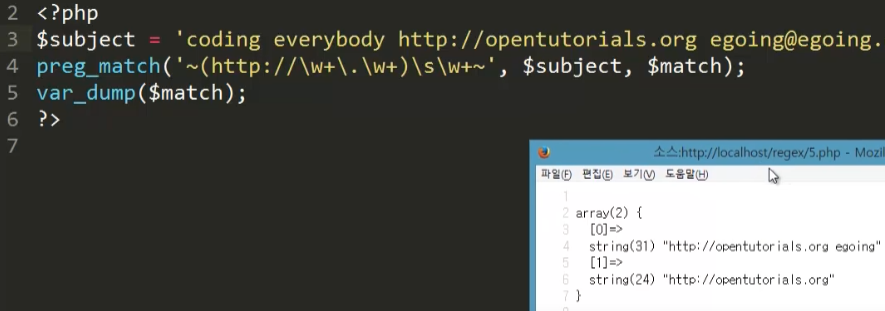
만약 우리가 좀더 많은 정보(홈페이지, 이메일, 전화번호)를 추출하고 싶다면
캡쳐링을 사용한다.

홈페이지 부분을 ( )로 감싸자 배열의 값이 두개가 됐다.

초록색 동그라미 부분을 인식시키기 위해서 \s로 공백을 넣었다.
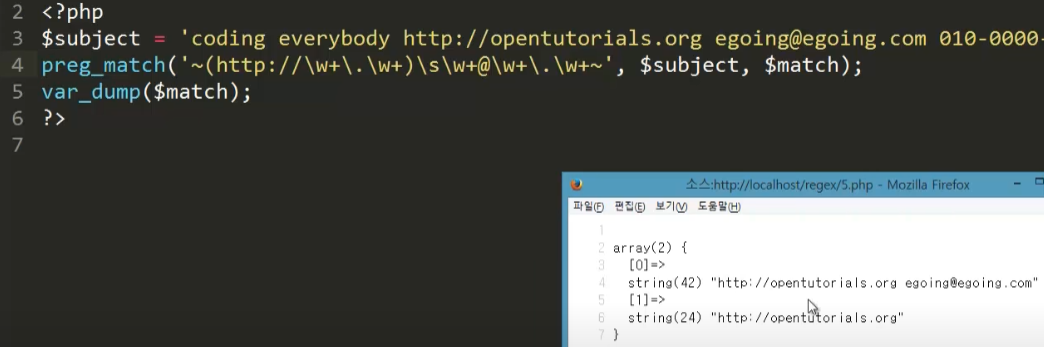
이메일도 ( ) 쳐주면 다음과 같이 된다.

즉, ( ) 로 묶인 구간은 독립적으로 추출해낼 수 있다.
= 캡쳐링 = 역참조

밑에 echo로 앱을 만들었다.


preg_match는 검색 결과가 있는지 없는지 여부를 확인하는 것이 기본적인 용법인데,
세 번째 인자로 변수를 부여하게 되면,
그 변수 안에는 ( ) 를 통해서 캡쳐링한 데이터가 들어온다.
그리고 그 데이터를 이용해서 우리가 앱을 만들 수 있다.

url에서 도메인(php.net) 추출하기
3행에 @가 앞 뒤로 나왔다 = @가 구분자라는 뜻
i는 대소문자를 구분하지 않겠다는 뜻이다.
앞에 있는 ^는 경계(행의 시작점)를 의미한다.
즉, http://로 시작하는 것을 검사한다.
?:을 붙이게 되면 해당 ( ) 안에 있는 내용은 $matches라는 변수 안에 담기지 않게 된다.
즉, ^을 부분적으로 적용하려고 ( )를 쓴것이지, http://를 변수로 담고 싶은 것은 아니기 때문에
?:를 붙인 것이다.


우리가 원하는 것은 위의 것인데, ?:를 빼면 아래와 같이 나온다.
?는 앞에 있는 것이 0~1개라는 것을 의미하는 수량자이다.

? 뒤쪽을 보자.
^은 [ ] 밖에서 사용될 때는
먼저 나온 ^처럼 행의 시작점을 의미하는 경계 지정자이다.
그런데 [ ] 안에서는 not을 의미한다.
즉 /가 아닌 문자 전체들을 의미한다.
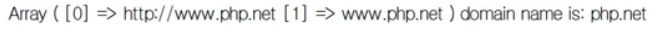
위에서 얻은 값을 $host에 넣었다.
뒤에 두 부분(php.net)만 추출해보자.

이번에는 구분자로 /를 사용하였다.
[ ] 안에서 ^의 의미는 부정이다.
.이 [ ] 안에 들어가면 임의의 문자를 의미하는 특수한 패턴이 아니라, 그냥 문자 .이 된다.
뒤에 +이 붙어있으므로, .이 아닌 문자가 1개 이상이라는 뜻이 된다.
\. escaping
$는 문자열의 끝을 의미한다.

우리가 검사하려고 하는 foobar: 2008이다.
최종결과:

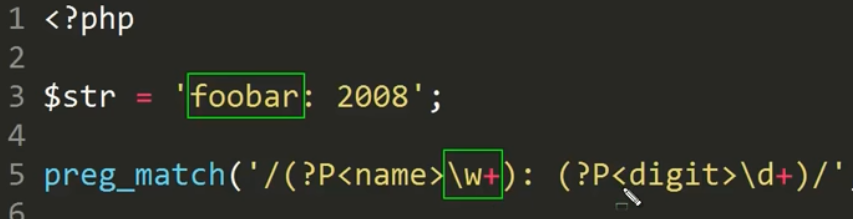
foobar는 \w+에 의해서 정의된다.
즉, 문자가 하나보다 많다면.
name은 배열 중의 key값을 의미한다.
:은 :을 의미한다.
\d는 숫자를 의미하고, +는 하나 이상을 의미한다.
각각의 덩어리는 서브 패턴 ( ) 으로 감싸주었다.
서브 패턴의 초입에 ?P< >는 key값을 의미한다.
이런 것을 Back reference라고 한다.
php에서는 입력한 순차적으로 서브 패턴의 값을 알려주는데,
조금더 정확하게 하기 위해서,
인덱스 대신에 연관 배열의 key값을 사용해서 그 패턴의 이름을 지정할 수 있다는 것이 이번 예제의 핵심이다.
19. 정규표현식 - 치환
정규표현식을 사용하는 목표 ① 검색 ② 치환
https://www.php.net/manual/en/function.preg-replace.php
PHP: preg_replace - Manual
Post slug generator, for creating clean urls from titles. It works with many languages.

pattern으로 들어온 값을 선택하고, 그 값을 replacement로 변경하고, subjrct는 변경하려는 대상이 되는 정보이다.


네모친 \w+는 April이고, 첫 번째 등장하는 1번 하위표현식이다.
${ 번호 }는 하위표현식 상에서 이 번호에 해당되는 하위표현식을 의미한다.

그래서 ${1}1은 April1이 된다.

$3은 세 번째 서브패턴의 값(2003)이다.



이전 예제와 비슷하지만,
patterns와 replacements가 배열이라는 것이 차이점이다.
quick → slow
brown → black
fox → bear

preg_replace의 세번째 인자(subject)는 subject 즉, 우리가 변경하려고 하는 문자열이다.
이것을 초록색 주석으로 변경하는 것이 이 예제의 목표이다.

preg_replace의 첫번째 인자($patterns)는 0, 1 두 개의 값을 갖고 있는 배열이다.

preg_replace의 두번째 인자($replace)또한 0, 1 두 개의 값을 갖고 있는 배열이다.
1) subject에서, $patterns 배열의 0번 값에 해당되는 부분을 찾아서, $replace 배열의 0번 값으로 바꾼다.
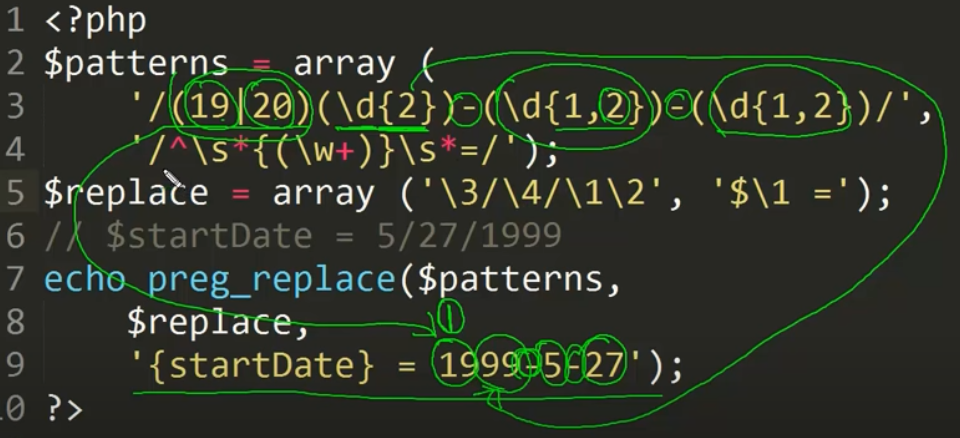
그럼 이것이 어떻게 변경되는가?
$\1 = 은 패턴이 아니다. 정규표현식의 문법이 아니다.
먼저 $가 들어오고, \1은 첫번째 서브패턴의 값(startDate)이다.
→ 주석과 같은 결과가 나온다.
2) subject에서, $patterns 배열의 1번 값에 해당되는 부분을 찾아서, $replace 배열의 1번 값으로 바꾼다.
^은 제일 처음이라는 뜻이다.
즉, {start 부분에서 시작한다는 뜻이다.
\s는 공백을 의미한다.
*는 0~多이므로 공백이 있을 수도 있고, 없을 수도 있다는 뜻이다.
\w+ = startDate이고, ( )로 묶여있으므로 첫 번째 서브패턴이 된다.
그럼 이것이 어떻게 변경되는가?

빨간 색으로 각각의 서브패턴이 몇 번째 서브패턴에 해당하는지 써보았다.
$1 = \1
→ 주석과 같은 결과가 나온다.
'PHP > 생활코딩' 카테고리의 다른 글
| 5/28 생활코딩 (0) | 2020.05.28 |
|---|---|
| 5/27(2) 생활코딩 (0) | 2020.05.27 |
| 5/26 생활코딩 (0) | 2020.05.27 |
| 5/25(3) 생활코딩 (0) | 2020.05.25 |
| 5/25(2) 생활코딩 (0) | 2020.05.25 |




댓글